ProMAG Reconstruction
We show a comparison of reconstruction results for our method ProMAG at different temporal compression ratios 4×, 8× and 16× temporal compression with our progressive growing approach. Note: For all cases in this work we use 8× spatial compression. ProMAG can achieve similar reconstruction quality without much degradation, even though we increase the temporal comression from 4× to 16× keeping the same number of channels in latent space.
16 channel Latent (zdim=16)
Ground-Truth
ProMAG-4×
ProMAG-8×
ProMAG-16×
Ground-Truth
ProMAG-4×
ProMAG-8×
ProMAG-16×
Methodology
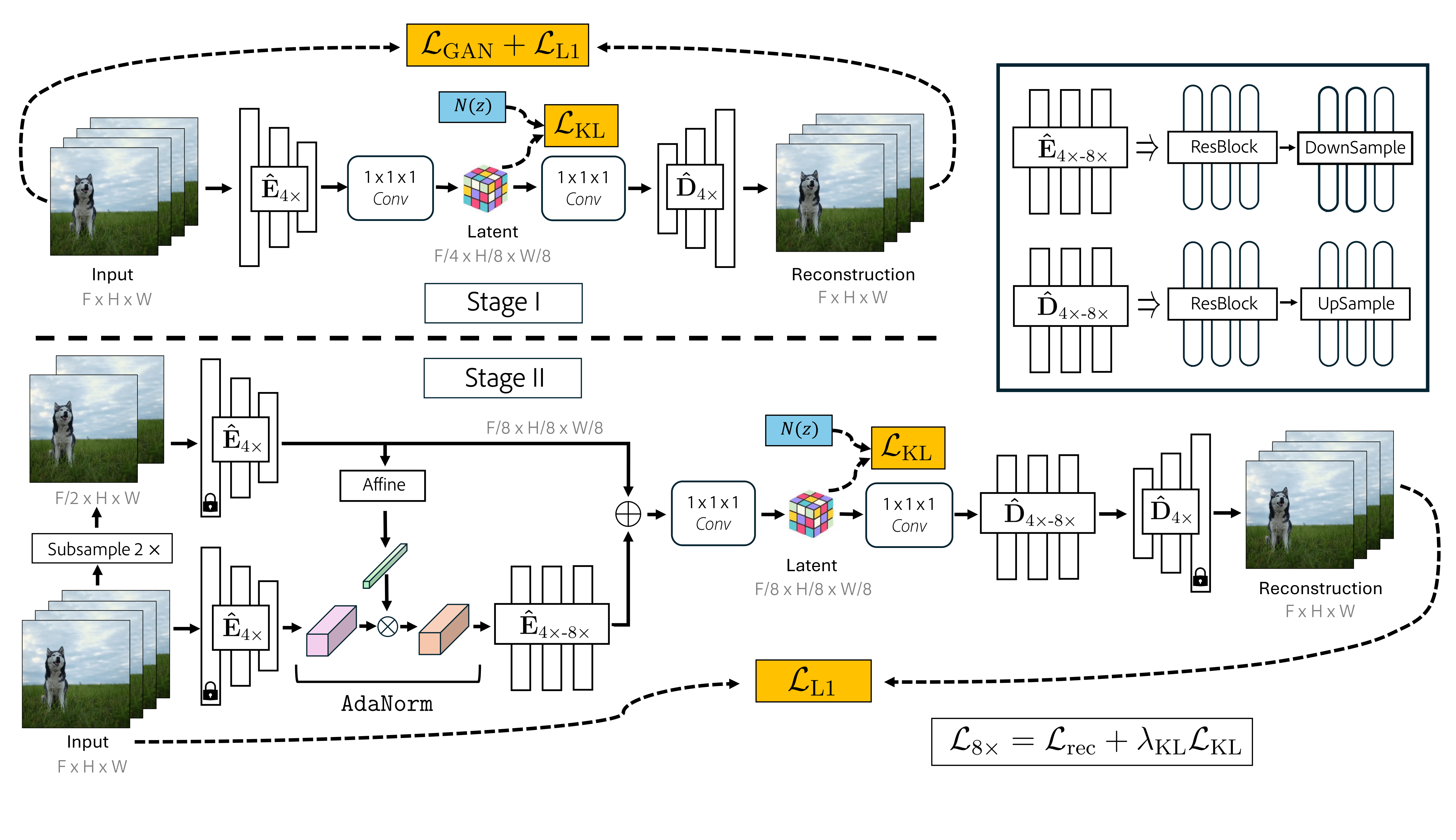
ProMAG training proceeds in two stages. During Stage I (top section), we train a base video tokenizer to perform 4× compression in time. During Stage II (bottom section), we grow the base model from Stage I with an addition 2× temporal compression to achieve a final temporal compression of 8×.
Reconstruction Comparison
We show a comparison of reconstruction results of directly extending MagViTv2 to 16× temporal compression against our method ProMAG at 16× with our progressive growing approach.
ProMAG at 16× temporal compression has much more accurate reconstructions and not not contain artifacts observed in the reconstruction results of directly extending MagViTv2 to 16× temporal compression.
For viewing more 16× temporal compression comparison results please refer to our Gallery > Reconstruction Comparison 16× page.
8 channel Latent (zdim=8)
Ground-Truth
MagViTv2-16×
ProMAG-16×
Ground-Truth
MagViTv2-16×
ProMAG-16×
Text-to-Video Generation
We show text-to-video generation results with our ProMAG-16× latent (16× temporal compression). Our highly compressed latent is friendly with video generation. DiT trained on this highly compressed latent can generate videos which accurately follow the prompts and generate realistic motion.
For viewing more 16× temporal latent space video generation results please refer to our Gallery > Text-to-Video Generation 16× Latent page.
Similar to MagViTv2, we encode and decode 17 frames (chunk) at a time. Thus we can observe jumps in text-to-video results every 17 frames in regions of high frequency details.
We show that training DiT with overlapped encoded frames can mitigate this issue.
Please refer to our Gallery > Text-to-Video Generation Overlapping Chunks page for results without flickering across chunks.
Note: Hover over the text to see the full prompt.
In the aerial view of Santorini, white Cycladic buildings with blue domes are...
Campfire at night in a snowy forest with starry sky in the background.
A dog wearing virtual reality goggles in sunset, 4k, high resolution.
An astronaut in a pressure suit is floating weightlessly among a breathtaking...
Extreme close-up of a 24-year-old woman's eye blinking, standing in Marrakech during magic hour, cinematic...
The camera rotates around a large stack of vintage televisions all showing different programs...
A stop-motion animation of a flower growing out of the windowsill of a suburban house.
An extreme close-up of a gray-haired man with a beard in his 60s, deep in thought pondering history...
In a post-apocalyptic world, a German Shepherd dog wearing a bulky spacesuit lies amidst vibrant...
A cute smiling Yorkshire Terrier dressed in a cyberpunk costume sits comfortably on a futuristic chair...
Illustration of a dog floating up into the sky in the flat vector rotoscoped style of "A Scanner Darkly."
An award-winning photo of a stylishly dressed elderly woman wearing very large glasses...
Text-to-Video Generation (Long Video)
We have shown theoritically that with our highly compact ProMAG-16× latent (16× temporal compression) space, we can generate 340 frames with same token budget as required to generate 68 frames with ProMAG-4× latent (4× temporal compression) space.
We show examples of text-to-video generation results for very long videos (14.1s). Videos results are consistent with the text prompt and contain realistic motion.
Generated videos are at 192×320 resolution and have 340 frames (around 14.1s at 24fps).
For viewing more long video generation results please refer to our Gallery > Text-to-Video Generation 16× Latent Long Video page.
Note: Hover over the text to see the full prompt.
A slow cinematic push in on an ostrich standing in a 1980s kitchen.
Starting from a ground-level view of a road leading towards a tunnel...
An irregular sphere shape ball, warps and explodes as it...
Apple transforming into
a baseball
Create a high-quality, realistic video portrait of an android posing against a black background...
A person sitting on a bed looking at a spectacular night sky full of galaxies and stars, view from behind...
An ultra-fast first-person POV hyper-lapse rapidly speeding through a forest fire into a snow capped...
Space Astronaut floating in space
in front of a Magnetic field
energy wormhole.